

【新智元导读】DeepMind最近被ICML 2024吸收的一篇论文free_porn_video,完统统全袒露了他们背靠谷歌的「豪横」。一篇著作预估了这项相关所需的算力和老本,八成是Llama 3预教师的15%,耗费资金可达12.9M好意思元。
发一篇顶会论文,需要若干实验预算?
最近,DeepMind发表了一项相关,对LLM扩大限度时多样算法和架构细节,比如参数和优化器的聘用,进行了辽远的实证拜谒。
这篇论文已被ICML 2024吸收。

论文地址:https://arxiv.org/abs/2407.05872
63页的论文涵盖了漫山遍野的模子,备选决策包括3种优化器、4种参数化决策、几种对都假定、十多个学习率,以及最高达26.8B的14种参数限度。
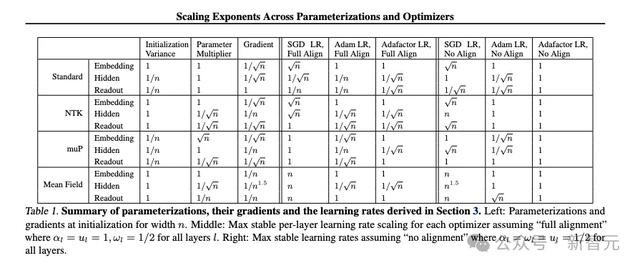
需要进行实验的4种参数化决策
只是听到这些数字,就不难知谈,这项相关必定波及海量的模子开动实验。
而有一位诚实读者,为了测试我方对论文内容的融合,统计了其中进行的系数实验,并估算出了复现论文的老本。
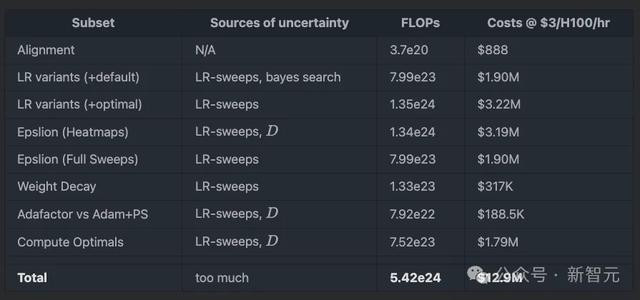
将所需算力全部加在沿路,琳琅满目,确凿达到了惊东谈主的1290万好意思元。
训练基本功的时刻到了,假如你是相关团队的leader,字据实验筹备对所需算力和老本进行预估是一项必不成少的本事。
那就让咱们随着这篇博客著作盘一遍,这一千多万好意思元,究竟烧在那里。
Transformer架构信息
论文附录C提供了对于模子算法和架构的多样细节建造,比如使用decoder-only架构、层归一化、GeLU激活函数、无dropout、T5分词器、批大小为256、用FSDP并行等等。
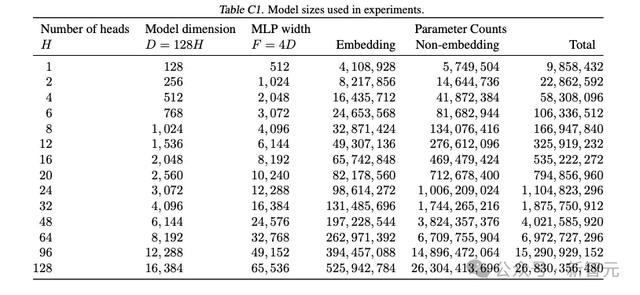
实验模子的参数限度统计
通过架构方面的信息,咱们不错约莫估算出教师中每个token所需的FLOPS,记为M。
由于论文莫得形容到任何GQA/MQA机制,是以就假定Rkv=1,此外还有lseq=512,Dhead=128,L=8(深度),V=32101(分词器词汇量)。
模子总参数目不错暗示为:
因此,就不错得到M的计较公式:
默许情况下,每次实验处置的token数(tokens per experiment, TPE)为5k(教师步数)×256(批大小)×512(lseq),约为6.5536e9。
defM(d: int, L=8, l_seq=512, V=32101) -> int:
return6*d * (L*(12*d + l_seq) + V)
TPE = 50000 * 256 * 512
对都实验
假定对都实验中,胜利使用了背面的学习率扫描得出的最优成果,并莫得单独进行学习率扫描,因此这一步的老本计较比较简便:

defalignment -> int:
return4 * TPE * sum(M(d) for d in [1024,2048,4096])
# >>> f'{alignment:.3E}'
# '3.733E+20'
# >>> cost_of_run(alignment)[0]
# 888.81395400704
淌若H100每开动1小时的破耗以3好意思元计较,对都实验的老本约莫为888好意思元。
学习率
子问题:最好评估吃亏(eval loss)实验
论文的表E1纪录了6种模子限度下,系数可能的优化器×参数化决策×模子大小×实验建造的组合,辞别进行基础学习率扫描,以得回最好评估吃亏。
悉数包括如下几个实验变量:
- 模子维度D∈3072,4096,6144,8192,12288,16384
- 4种参数化决策
- 3种优化器,其中SGD仅有5个实验建造,Adam和Adam+Param Scaling有7个实验建造
假定这里的实验都是单独进行,莫得从其他地点复制成果,因此淌若全部开动一遍,有老本上限预估:
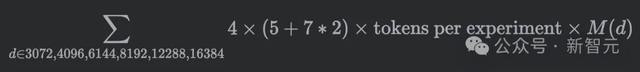
H = [1,2,4,6,8,12,16,20,24,32,48,64,96,128]
D = [h * 128for h in H]
deftable_e1 -> int:
sets_x_optims = 5 + 7 + 7
return4 * sets_x_optims * TPE * sum(M(d) for d in D[-6:])
# >>> f'{table_e1:.3E}';cost_of_run(table_e1)
# '1.634E+23'
# (388955.9991064986, 16206.499962770775)
这部分的老本就接近40万好意思元,天然仍属于可袭取界限内,但对于大大都学术预算来说free_porn_video,还是算瑕瑜常腾贵了。
表E1给出了最好评估吃亏,但莫得形容LR的扫描政策,每张图上的点数也不尽换取。
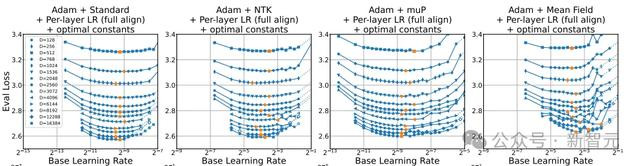
由于莫得得到论文作家的恢复,咱们也无法详情具体机制,因此假定每个最好评估吃亏都经由了15次实验(目测发现,每条线的点数约为10~15)。
β参数
字据论文4.2节内容,学习率还波及到两个超参数的聘用:β和γ。
淌若仅有β参数,则被称为「LR+default」建造:
这部分包括3×优化器,4×参数化,加上全局和单层(GlobalLR、Perlayer-fullalign)辞别进行实验,以及未知的LR扫描数目:

defbeta_only -> int:
return3*4*2*PpL * TPE * sum(M(d) for d in D)
# 7.988E+23 (1902022.3291813303, 79250.93038255542)
从公式就不错看出,老本和下文的epsilon实验雷同,都是200万好意思元。
γ参数
比较β参数的实验,这部分有两个细节各别。
最初,除了GlobalLR、Perlayer-fullalign两种建造外,还需要加上Perlayer-noalign建造。

其次,仅针对d=1024=b,进行3D超参数搜索(γ_1,γ_h,γ_L+1),因此有零碎的800次开动。

两者集中后的计较公式为:
这部分的预估老本与Adam的epsilon热力求实验接近,约为320万好意思元。
defgamma_expts -> int:
return36*TPE * (800*M(1024) + PpL*sum(M(d) for d in D))
# gamma_expts 1.354E+24 (3224397.534237257, 134349.8972598857)
Adam优化器的Epsilon参数
论文4.3节所述的Epsilon参数实验是计较量的大头。
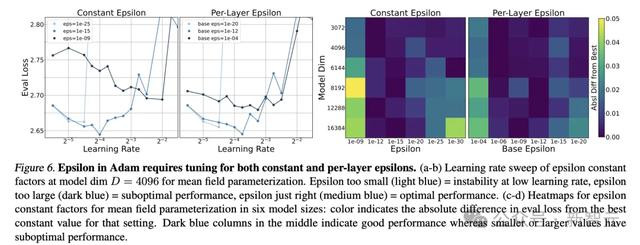
字据上头的推断,每次找到最好评估吃亏机都尝试过15个不同的学习率(points per line),那么图6所示的epsilon参数变化图耗费的计较量为:

计较成果炫夸出一种爽朗的腾贵,也即是200万好意思元的账单云尔。
PpL = 15# unprincipled estimate
defeps_variants -> int:
return4 * 6 * PpL * TPE * sum(M(d) for d in D)
'''
>>> f'{eps_variants:.3E}';cost_of_run(eps_variants)
'7.988E+23'
(1902022.3291813303, 79250.93038255542)
'''
除了图6左侧的折线图,还有附录F热力求的成果。
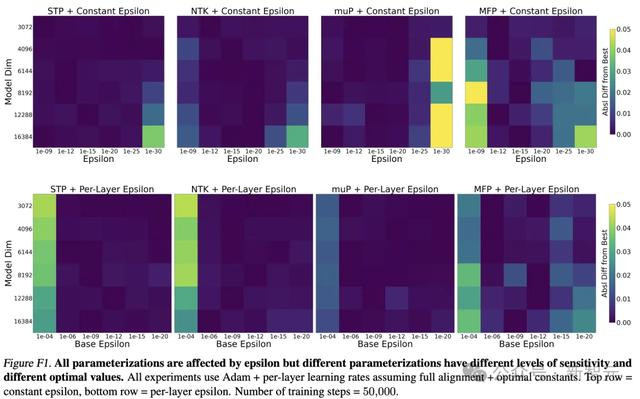
假定每个方块值都是经由13次学习率扫描后得到的成果,这部分计较量则为:
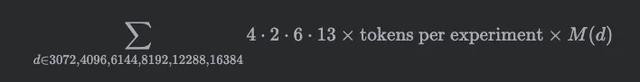
成果发现,只是要得到这8张热力求,老本即是320万好意思元。况且,由于咱们将LR扫描数目建模为常数13,这个数字可能低于施行老本。
defeps_heatmaps -> int:
# eps-type * eps-val * parameterizations * LR range * ...
return2 * 6 * 4 * 13 * TPE * sum(M(d) for d in D[-6:])
'''
>>> f'{eps_heatmaps:.3E}';cost_of_run(eps_heatmaps)
'1.341E+24'
(3193533.466348094, 133063.89443117057)
'''
权重衰减
权重衰减实验(附录G)比较好融合,对4×参数化决策以及系数参数进行一次基本的LR扫描:

比epsilon实验低廉不少,也即是湾区工程师一年的工资——31.7万好意思元。
defweight_decay -> int:
return4 * PpL * TPE * sum(M(d) for d in D)
'''
>>> f'{weight_decay:.3E}'; cost_of_run(weight_decay)
'1.331E+23'
(317003.7215302217, 13208.488397092571)
'''
Adafactor优化器
这部分实验在附录C3中有详确形容,是为了考研Adafactor和Adam+parameter scaling是否有相通的宽度缩放机制。
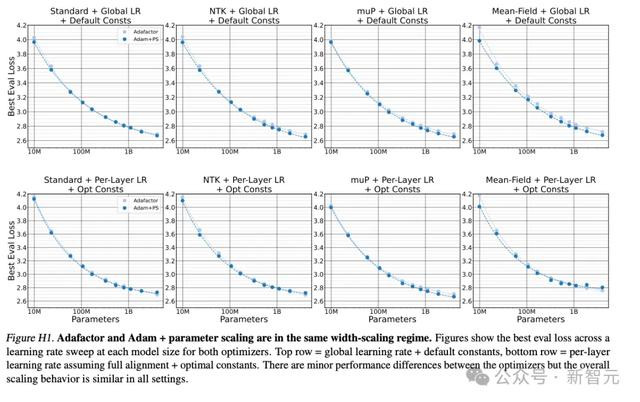
共有2×4张图,其中每个优化器汇注11个数据点,因此计较公式为:

账单上再加18.8万好意思元。
defadafactor -> int:
return2*2*4*PpL*TPE*sum(M(d) for d in D[:11])
'''
>>> f'{adafactor:.3E}'; cost_of_run(adafactor)
'7.918E+22'
(188532.80765144504, 7855.533652143543)
'''
计较最优化
论文尝试更变注眼力头H的数目,但愿找到计较最优化的建造,但其中波及步长和数据集的更变,因此这部分不使用公式形容,计较代码如下:
defP(d: int, L=8, V=32101) -> int:
return2 * d * (6*L*d + V)
defcompute_optimal:
indices_50k = (14, 14, 12)
return4*PpL*sum([
TPE * sum(sum( M(d) for d in D[:i] ) for i in indices_50k),
20 * sum(P(d)*M(d) for d in D[:11]) *3,
])
# compute_optim 7.518E+23 (1790104.1799513847, 74587.67416464102)
精采
将以上各部分实验的算力和老本汇总在沿路:
alignment 3.733E+20 (888.81395400704, 37.033914750293334)
table_e1 1.634E+23 (388955.9991064986, 16206.499962770775)
eps_variants 7.988E+23 (1902022.3291813303, 79250.93038255542)
eps_heatmaps 1.341E+24 (3193533.466348094, 133063.89443117057)
beta_only 7.988E+23 (1902022.3291813303, 79250.93038255542)
gamma_expts 1.354E+24 (3224397.534237257, 134349.8972598857)
weight_decay 1.331E+23 (317003.7215302217, 13208.488397092571)
adafactor 7.918E+22 (188532.80765144504, 7855.533652143543)
compute_optim 7.518E+23 (1790104.1799513847, 74587.67416464102)
成果发现,整篇论文的运算量为5.42e24 FLOPS。
这个数字只是是Llama 3教师计较量的15%,淌若在10万卡H100集群上开动,只需要2天时辰即可完成系数实验。
total_flops=5.421E+24
rental price: US$12.9M
h100 node months required: 746.9595590938408
(sanity check) D=[128, 256, 512, 768, 1024, 1536, 2048, 2560, 3072, 4096, 6144, 8192, 12288, 16384]
(sanity check) modelsizes: ['0.00979B', '0.0227B', '0.058B', '0.106B', '0.166B', '0.325B', '0.534B', '0.794B', '1.1B', '1.87B', '4.02B', '6.97B', '15.3B', '26.8B']
(sanity check) M/6P: ['63.4%', '68.5%', '75.3%', '79.7%', '82.8%', '86.8%', '89.3%', '91.0%', '92.2%', '93.9%', '95.7%', '96.7%', '97.7%', '98.3%']
然而,淌若不从LLM预教师的规范来臆想,仅把DeepMind的这篇论文看作念一篇学术相关,这个计较量就显得相称奢侈了。
淌若实验室仅有10张H100,就压根不成能进行这个量级的相关。
有100张H100的大型实验室free_porn_video,未必能用几年时辰跑完以上系数实验。




